
パーマリンクとは?意味と使い方を解説します!
2019年11月25日
東証スタンダード上場企業のジオコードが運営!
SEOがまるっと解るWebマガジン
更新日:2024年 01月 19日
 robots.txtとは?作り方・書き方・確認方法を解説します
robots.txtとは?作り方・書き方・確認方法を解説します

【監修】株式会社ジオコード SEO事業 責任者
栗原 勇一
SEOはユーザーだけでなく、検索エンジンへの配慮も大切です。
時には、「クローラー(検索エンジン)の制御」を求められることもあります。
今回は、クローラー制御の役割を担う「robots.txt」ファイルについて解説します。
また、SEOについて動画で学びたい!という方のために、動画セミナーをご用意しています。
あわせてご覧ください。
▼人気の動画はこちら




目次
検索エンジンは「クローラー」というプログラムでWebサイトを巡回し、情報を収集します。
robots.txtは、その「クローラー」の動きを制御するファイルです。
robots.txtには、大きく分けて2つの用途があります
・ページのアクセス可否を制御する
・クローラーにsitemap.xmlの場所を教える
要するに、見てほしくないページをクローラーが巡回しないように設定できます。
また、Webサイトの案内板であるsitemap.xmlの場所をクローラーに伝えることもできます。
クローラーに対して評価してほしいページの巡回を促進したり、評価してほしくないページを評価対象から除外することができます。
ちなみに、ファイル名は「robots.txt」(ロボッツドットテキスト)なので気を付けてください。
ファイル名は固定なので間違えると機能しません。
イージーミスには気を付けましょう。
robots.txtを作成し、アップロードするまでに必要な作業を説明します。
具体的な記述については、別セクションで解説していますので、少々お待ちください。
テキストエディタを開いて「robots.txt」というファイル名で保存してください。
※テキストエディタ:「メモ帳」や「秀丸」みたいにテキストを編集するソフトの総称
たくさんの種類がありますが、何のエディタでも構いません。
デフォルトでPCに入っている、メモ帳でも大丈夫です。
この段階ではとりあえず、中身は何も書かなくても大丈夫です。
robots.txtを作成したら、サーバーにアクセスし、該当サイトのルートディレクトリ(TOPページと同じ階層)にアップロードしてください。
設置場所は固定ですので、間違えないようにしてくださいね。
robots.txtには下記4項目を記述できます。
全て記述しなければいけない訳ではなく、必要な項目のみを記述します。
| 命令 | 必須or任意 | 記述の意味 |
|---|---|---|
| User-agent | 必須 | アクセスを制御したいロボットの種類を指定 Googlebot と指定すれば、Googleのクローラーを制御できる 全てのロボットのアクセスを制御する場合は”*” を記入 |
| Disallow | 任意 | クロールをブロックしたいディレクトリやページを記入する 全てのページに対してアクセスを制限したい場合は”/”を記述 |
| Allow | 任意 | アクセスを許可する記述 Disallowによりブロックしているディレクトリの一部をクロールさせたい時などに使用 |
| Sitemap | 任意 | クローラーが巡回しやすいようにサイトマップの場所を指定 サイトマップでは巡回してほしいURLをクローラーに伝えることができる |
では、それぞれ「書き方」と「何を書けばいいのか」を解説します!
「User-agent」では制御を行うクローラーの種類を指定します。
下記のように記述します。
User-agent: *
User-agent: Googlebot
上の例の * はアスタリスクと言って、全部を意味します。
「全部のクローラーが対象」という意味になりますね。
指定できるクローラーはGoogleだけでなく、その他の検索エンジンも可能です。
Googleとその他のクローラーを、一部ではありますが紹介します。
| クローラー | UA(ユーザーエージェント) |
|---|---|
| Google web検索 | Googlebot |
| 画像用 Googlebot | Googlebot-image |
| 動画用 Googlebot | Googlebot-Video |
| ニュース用 Googlebot | Googlebot-News |
| AdSense | Mediapartners-Google |
| AdsBot(PCの広告品質チェック) | AdsBot-Google |
| モバイルウェブ用 AdsBot (モバイルの広告品質チェック) | AdsBot-Google-mobile |
「Googlebot」のユーザーエージェントをブロックした場合、Googleの他のユーザーエージェントもブロックされますので、その点ご認識ください。
その他のGoogleユーザーエージェントは、こちらで確認できます。
https://support.google.com/webmasters/answer/1061943
その他のユーザーエージェントの紹介です。
| クローラー | UA(ユーザーエージェント) |
|---|---|
| 検索エンジン「MSN」 | msnbot |
| 検索エンジン「Bing」 | bingbot |
| 検索エンジン「Yahoo!」 | Yahoo!Slurp |
| 検索エンジン「Yahoo!Japan」 | Y!J |
| 中国の検索エンジン「Baidu」 | Baidu |
| ロシアの検索エンジン「Yandex」 | YandexBot |
| Twitterbot | |
| facebookexternalhit |
もちろんこちらで紹介したクローラーが全てではありません。
数が多いので、あくまで一例になります。
Disallowは「アクセス制限」の記述です。
記述したディレクトリやページは、検索エンジンがクロールしなくなります。
具体的な記述例は下記になります。
User-agent: *
Disallow: /
この記述の意味は「全ページアクセスしないでね」です。
「全てのクローラーは全てのページにアクセスしてはいけません」という意味ですね。
User-agent: *
Disallow: /seo/
この記述は「/seo/のディレクトリ配下にはアクセスしないでね」になります。
「/seo/link.html」や「/seo/price/」など、配下のページは全て制限の対象になります。
User-agent: *
Disallow: /seo/service.html
この記述は「/seo/service.html(ページ単体)にはアクセスしないでね」になります。
他のページにはアクセスできます。
User-agent: *
Disallow: /*?
こちらの記述は「パラメータを含むURLにはアクセスしないでね」になります。
「/?sort=〇〇」や「/?type=〇〇」のような記述があるURLを見たことはありませんか?
この「?」以下の部分がパラメータです。
パラメータは並び替えや絞り込みの使用など、重複URLが発生する可能性が高い要素です。
アクセス制御できれば、余計なクロールを防げそうですね。
※一例を書いておきますね。(実在しないURLです)
①:http://gc-seo.jp/shop/bag
②:http://gc-seo.jp/shop/bag/?sort=01
③:http://gc-seo.jp/shop/bag/?sort=02
上記「①は商品一覧ページ」のURLと仮定します。
「②と③は”並び替え”を行ったページ」のURLです。
全てのページにアクセスできると、重複コンテンツが認識されてしまいます。
先ほど紹介した設定を行うことで、クローラーが①のみアクセスするようにできます。

※補足説明
紹介した設定は「他のパラメータのページ」のアクセスも制限しています。
もしかしたら、本来アクセスしてほしいページまで制限をかけてしまうかもしれません。
こういったケースでは、下記のような設定で「sort」パラメータのみ制限可能です。
User-agent: *
Disallow: /?sort=*
設定したことがない人は難しいかもしれませんね…
難しい方も慣れている方も「robots.txtテスター」で一度テストすることをおすすめします。
本番反映前に、意図した通り処理されるかを確認できます。
テスターの使い方は後述していますので、わからない方は見てみてくださいね!
Allowはアクセス許可の記述です。
基本的には書かなくて大丈夫です。(書かなくてもクロールします)
Disallowで制限をかけたディレクトリの一部にアクセスしてほしい場合などに使用します。
記述例を紹介します。
User-agent:*
Disallow: /ranking/
Allow: /ranking/osaka
「/ranking/」配下が制限対象ですが「/ranking/osaka」だけはアクセス可能です。
このように、限定的にアクセスを許可する場合に使用するのがAllowになります。
sitemap.xmlを用意しておくと、クローラーに巡回してほしいURLを伝えることができます。
robots.txtでは「sitemap.xmlの場所」を検索エンジンに伝えることが可能です。
記述は下記になります。
Sitemap : https://〇〇〇.com/sitemap.xml
どこをクロールすればいいか明確になりますので、Googleから見てもありがたいファイルですね。
設定して損はないので、sitemap.xmlを用意し、robots.txtに場所を書いておきましょう。
robots.txtとsitemap.xmlの関係性は、以下のように置き換えて考えると分かりやすくなります。
①robots.txt:ビルのエントランスで案内してる人
➁sitemap.xml:ビルの案内板
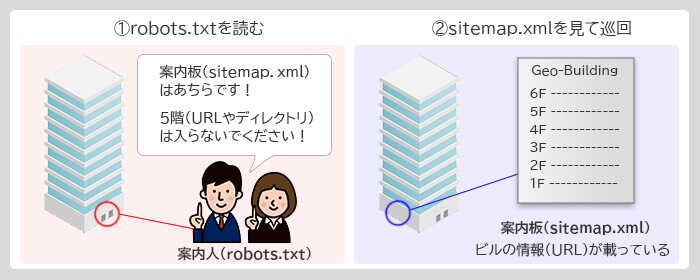
案内人(robots.txt)が最初に入っちゃいけない場所(Disallow)や、案内板(sitemap.xml)の場所を教えてくれます。
クローラーは指示通りに案内板(sitemap.xml)を読んで、ビル(サイト)を巡回します。
案内板にはビル全体の情報が載っていますが、STAFF ONLYの場所とか、OPEN前のフロアの情報は普通載っていません。
つまりrobots.txtが最初のご案内で、その後sitemap.xmlを見せて「巡回OKなページ」だけにクローラーを案内できるのです。
robots.txtの処理について、2点注意があります。
意図した通りの処理を行うため、予め知っておくと便利です!
コンテンツの品質が低いページなど、インデックスを削除するケースが存在します。
ですがインデックス削除にDisallowは使用しないでください。
インデックス削除を行うには、ページ内に「noindexタグ」を記入し、「インデックスから削除して!」と検索エンジンに伝えます。
Disallowを使うとそもそもページに行きませんので、「noindexタグ」を見つけることができなくなってしまいます。
※下記図のようなイメージです。
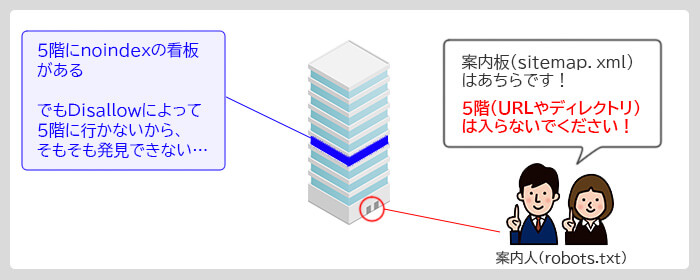
これでは「インデックスから削除して!」というシグナルが(Googleに)伝わりません。
ですので、インデックス削除にDisallowは使用しないでください。
robots.txtの処理の優先度は下記の二つを覚えておいてください。
①:階層が深い方から処理される
②:AllowがDisallowより優先される
例えば下記の記述をしたとします。
User-agent:*
Disallow: /ranking/osaka
Allow: /ranking/
一見、下記処理のように見えますが、違います。
①:/ranking/osakaへのアクセスを禁止!
②:やっぱり/ranking/以下は全部入ってもいいよ。
このケースでは「/ranking/osaka」の方が深い階層にあります。
後から上の階層(/ranking/)に対する「Allow」の処理を書いても、階層が浅いため優先度が低く、処理されないわけですね。
「robots.txtテスター」では、robots.txtの記述の検証ができます。
SearchConsoleのツールですが、2019年11月現在新SearchConsoleには移行されていません。
上記リンクよりアクセスしてみてください。
※SearchConsoleの登録・ログインが必要になります。
使い方は簡単、記述を書いて右下の「テスト」ボタンを押すだけです。
なお、URL入力はドメイン部分は不要です。
頭の「/」も最初から含まれてますので、書かないようにしてくださいね。
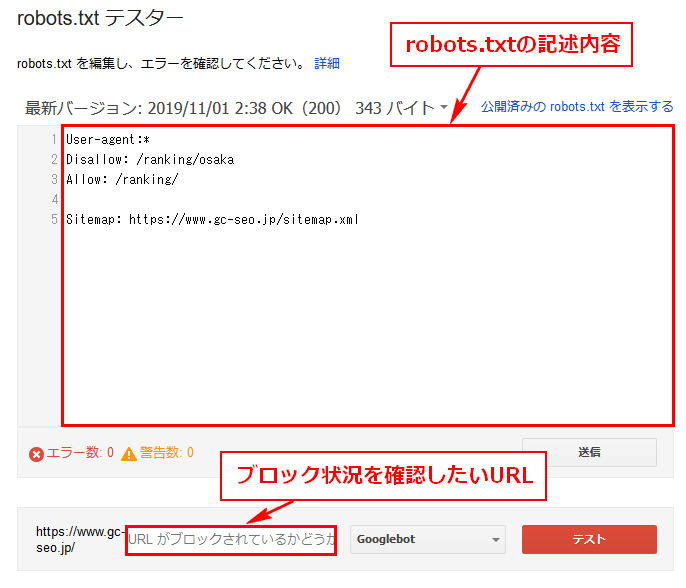
robots.txtの記述は「処理の優先度」の項目で紹介した下記になります。
User-agent:*
Disallow: /ranking/osaka
Allow: /ranking/
文字を読みやすいようにブラウザサイズを調整していますので、お使いのPCではもう少し横長になるかと思います。
では、実際にいくつか試してみましょう!
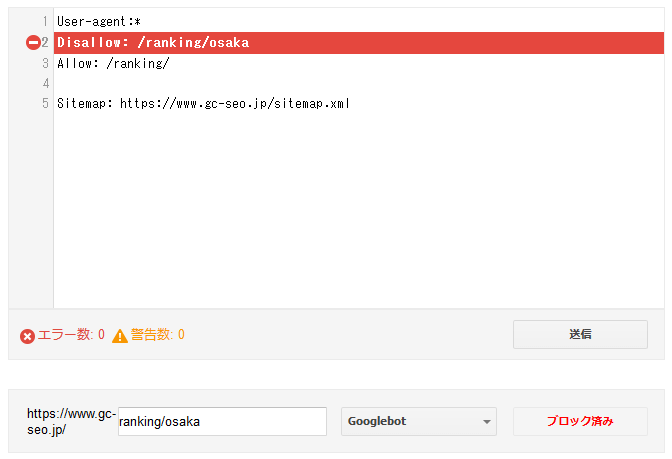
https://www.geo-code.co.jp/seo/ranking/osaka
上記URLのアクセスがブロックされているかのテストです。
右下の「ブロック済み」から、クローラーがアクセスできない状態だとわかります。
また、robots.txtの記述のアクセスブロック箇所が赤でハイライトされています。
どの記述でブロックされているか、一目でわかりますね。
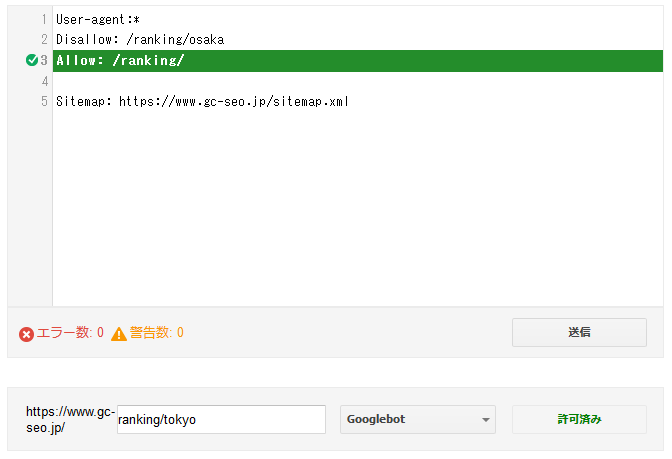
https://www.geo-code.co.jp/seo/ranking/
今度は一つ上の階層へのアクセスが、ブロックされているかをチェックしてみました。
結果は「許可済み」なのでアクセスできることがわかります。
Allowでアクセスを許可している場合は、記述が緑色でハイライトされます。
こちらもわかりやすいですね。
Allowの記述がない場合は、ハイライトはなしで右下が「許可済み」になります。
テスターは特にリスクもなく、存在しないURLの検証もOKです。
設定ミスがあると、クローラーがアクセスできないこともあるので、
必ず検証してから本番に実装しましょう。
竹内の言う通り、robots.txtの扱いは慎重に行いましょう。
クローラーが全ページアクセスできなくなってしまったら、順位が急落することもないとは言えません…
robots.txtは簡単に作成できますので、その分怖いファイルとも言えます。
ですが、Web担当をやっていれば触れることも結構あるファイルになります。
注意点や取り扱いについて、わからないまま作業しないでくださいね。
「対応方法が分からない」「自分でやるのは難しい」とお悩みの方は
実装も可能なジオコードのSEOがおすすめです!

ゴールはCV獲得!SEO、コンテンツマーケティング、UI・UX改善で、成果にコミット!
東証スタンダード上場企業が支援。18年間のノウハウを全て提供!SEO内製化を支援する唯一無二のサービス
リスティング、SNS、動画広告まで、ありとあらゆる業種で成果にコミット!
マーケティング会社だから出来るWeb制作!「SEO」「UI 設計」「記事コンテンツ」が標準搭載!
見込み顧客の獲得、育成から、商談管理、顧客管理まで、MA、SFA、CRMの全てを搭載!
自動集計で間違いなし!申請、確認の手間を大幅削減!クラウド勤怠管理、交通費精算、経費精算ツール、ネクストICカード
Webマーケティング&営業DXで、集客から、受注までの全てを一社完結
「社会の模範となる、唯一無二の魅力的な会社を創る仲間」を募集しています
ネクストSFAのジオコードによる、営業組織を強くするWebマガジン
基礎から最新のトレンド情報まで、SEOのことがまるっと解るWebマガジン
RLSA?CPA?用語が多すぎるWeb広告、基礎から学べるWebマガジン
Web制作の現場で良く使われる用語や技術について、基本が解るWebマガジン














